Load Test LiteLLM
How to run a locust load test on LiteLLM Proxy
- Add
fake-openai-endpointto your proxy config.yaml and start your litellm proxy litellm provides a free hostedfake-openai-endpointyou can load test against
model_list:
- model_name: fake-openai-endpoint
litellm_params:
model: openai/fake
api_key: fake-key
api_base: https://exampleopenaiendpoint-production.up.railway.app/
pip install locustCreate a file called
locustfile.pyon your local machine. Copy the contents from the litellm load test located hereStart locust Run
locustin the same directory as yourlocustfile.pyfrom step 2locustOutput on terminal
[2024-03-15 07:19:58,893] Starting web interface at http://0.0.0.0:8089
[2024-03-15 07:19:58,898] Starting Locust 2.24.0Run Load test on locust
Head to the locust UI on http://0.0.0.0:8089
Set Users=100, Ramp Up Users=10, Host=Base URL of your LiteLLM Proxy
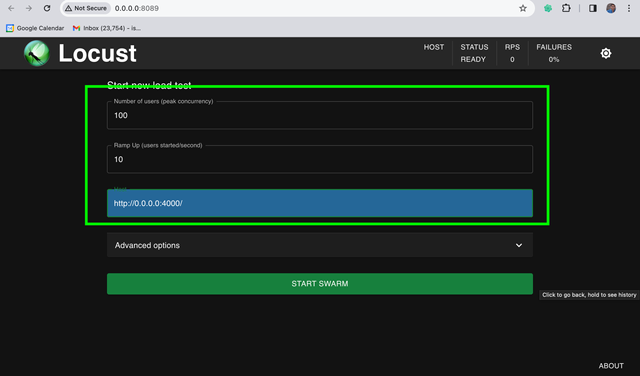
Expected Results
Expect to see the following response times for
/health/readinessMedian → /health/readiness is150msAvg → /health/readiness is
219ms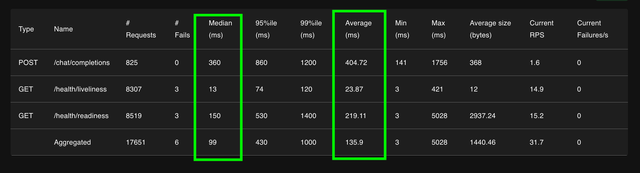
Load Test LiteLLM Proxy - 1500+ req/s
1500+ concurrent requests/s
LiteLLM proxy has been load tested to handle 1500+ concurrent req/s
import time, asyncio
from openai import AsyncOpenAI, AsyncAzureOpenAI
import uuid
import traceback
# base_url - litellm proxy endpoint
# api_key - litellm proxy api-key, is created proxy with auth
litellm_client = AsyncOpenAI(base_url="http://0.0.0.0:4000", api_key="sk-1234")
async def litellm_completion():
# Your existing code for litellm_completion goes here
try:
response = await litellm_client.chat.completions.create(
model="azure-gpt-3.5",
messages=[{"role": "user", "content": f"This is a test: {uuid.uuid4()}"}],
)
print(response)
return response
except Exception as e:
# If there's an exception, log the error message
with open("error_log.txt", "a") as error_log:
error_log.write(f"Error during completion: {str(e)}\n")
pass
async def main():
for i in range(1):
start = time.time()
n = 1500 # Number of concurrent tasks
tasks = [litellm_completion() for _ in range(n)]
chat_completions = await asyncio.gather(*tasks)
successful_completions = [c for c in chat_completions if c is not None]
# Write errors to error_log.txt
with open("error_log.txt", "a") as error_log:
for completion in chat_completions:
if isinstance(completion, str):
error_log.write(completion + "\n")
print(n, time.time() - start, len(successful_completions))
time.sleep(10)
if __name__ == "__main__":
# Blank out contents of error_log.txt
open("error_log.txt", "w").close()
asyncio.run(main())
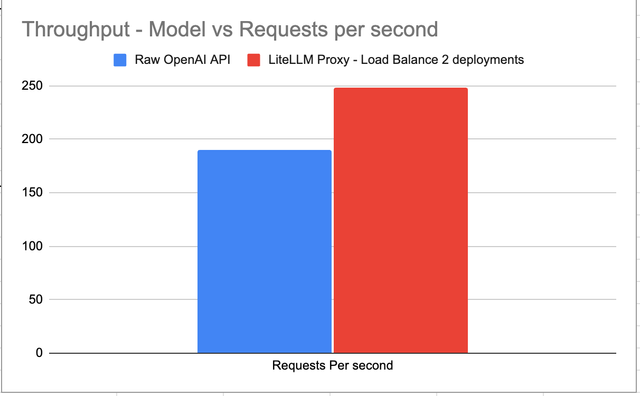
Throughput - 30% Increase
LiteLLM proxy + Load Balancer gives 30% increase in throughput compared to Raw OpenAI API
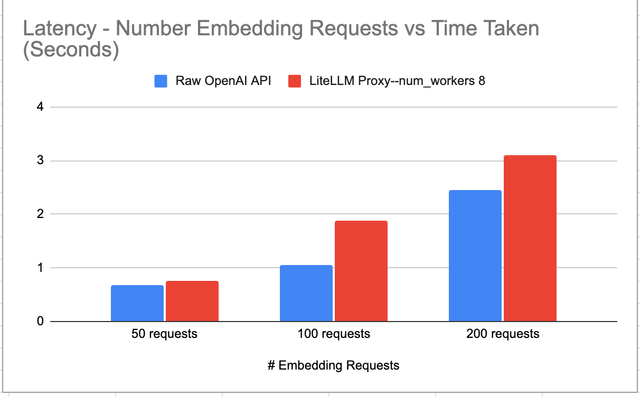
Latency Added - 0.00325 seconds
LiteLLM proxy adds 0.00325 seconds latency as compared to using the Raw OpenAI API
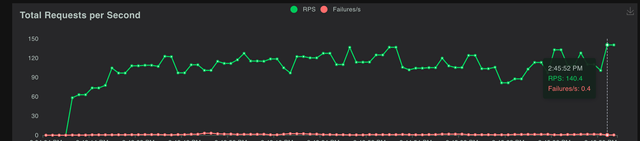
Testing LiteLLM Proxy with Locust
- 1 LiteLLM container can handle ~140 requests/second with 0.4 failures
Load Test LiteLLM SDK vs OpenAI
Here is a script to load test LiteLLM vs OpenAI
from openai import AsyncOpenAI, AsyncAzureOpenAI
import random, uuid
import time, asyncio, litellm
# import logging
# logging.basicConfig(level=logging.DEBUG)
#### LITELLM PROXY ####
litellm_client = AsyncOpenAI(
api_key="sk-1234", # [CHANGE THIS]
base_url="http://0.0.0.0:4000"
)
#### AZURE OPENAI CLIENT ####
client = AsyncAzureOpenAI(
api_key="my-api-key", # [CHANGE THIS]
azure_endpoint="my-api-base", # [CHANGE THIS]
api_version="2023-07-01-preview"
)
#### LITELLM ROUTER ####
model_list = [
{
"model_name": "azure-canada",
"litellm_params": {
"model": "azure/my-azure-deployment-name", # [CHANGE THIS]
"api_key": "my-api-key", # [CHANGE THIS]
"api_base": "my-api-base", # [CHANGE THIS]
"api_version": "2023-07-01-preview"
}
}
]
router = litellm.Router(model_list=model_list)
async def openai_completion():
try:
response = await client.chat.completions.create(
model="gpt-35-turbo",
messages=[{"role": "user", "content": f"This is a test: {uuid.uuid4()}"}],
stream=True
)
return response
except Exception as e:
print(e)
return None
async def router_completion():
try:
response = await router.acompletion(
model="azure-canada", # [CHANGE THIS]
messages=[{"role": "user", "content": f"This is a test: {uuid.uuid4()}"}],
stream=True
)
return response
except Exception as e:
print(e)
return None
async def proxy_completion_non_streaming():
try:
response = await litellm_client.chat.completions.create(
model="sagemaker-models", # [CHANGE THIS] (if you call it something else on your proxy)
messages=[{"role": "user", "content": f"This is a test: {uuid.uuid4()}"}],
)
return response
except Exception as e:
print(e)
return None
async def loadtest_fn():
start = time.time()
n = 500 # Number of concurrent tasks
tasks = [proxy_completion_non_streaming() for _ in range(n)]
chat_completions = await asyncio.gather(*tasks)
successful_completions = [c for c in chat_completions if c is not None]
print(n, time.time() - start, len(successful_completions))
# Run the event loop to execute the async function
asyncio.run(loadtest_fn())
Multi-Instance TPM/RPM Load Test (Router)
Test if your defined tpm/rpm limits are respected across multiple instances of the Router object.
In our test:
- Max RPM per deployment is = 100 requests per minute
- Max Throughput / min on router = 200 requests per minute (2 deployments)
- Load we'll send through router = 600 requests per minute
If you don't want to call a real LLM API endpoint, you can setup a fake openai server. See code
Code
Let's hit the router with 600 requests per minute.
Copy this script 👇. Save it as test_loadtest_router.py AND run it with python3 test_loadtest_router.py
from litellm import Router
import litellm
litellm.suppress_debug_info = True
litellm.set_verbose = False
import logging
logging.basicConfig(level=logging.CRITICAL)
import os, random, uuid, time, asyncio
# Model list for OpenAI and Anthropic models
model_list = [
{
"model_name": "fake-openai-endpoint",
"litellm_params": {
"model": "gpt-3.5-turbo",
"api_key": "my-fake-key",
"api_base": "http://0.0.0.0:8080",
"rpm": 100
},
},
{
"model_name": "fake-openai-endpoint",
"litellm_params": {
"model": "gpt-3.5-turbo",
"api_key": "my-fake-key",
"api_base": "http://0.0.0.0:8081",
"rpm": 100
},
},
]
router_1 = Router(model_list=model_list, num_retries=0, enable_pre_call_checks=True, routing_strategy="usage-based-routing-v2", redis_host=os.getenv("REDIS_HOST"), redis_port=os.getenv("REDIS_PORT"), redis_password=os.getenv("REDIS_PASSWORD"))
router_2 = Router(model_list=model_list, num_retries=0, routing_strategy="usage-based-routing-v2", enable_pre_call_checks=True, redis_host=os.getenv("REDIS_HOST"), redis_port=os.getenv("REDIS_PORT"), redis_password=os.getenv("REDIS_PASSWORD"))
async def router_completion_non_streaming():
try:
client: Router = random.sample([router_1, router_2], 1)[0] # randomly pick b/w clients
# print(f"client={client}")
response = await client.acompletion(
model="fake-openai-endpoint", # [CHANGE THIS] (if you call it something else on your proxy)
messages=[{"role": "user", "content": f"This is a test: {uuid.uuid4()}"}],
)
return response
except Exception as e:
# print(e)
return None
async def loadtest_fn():
start = time.time()
n = 600 # Number of concurrent tasks
tasks = [router_completion_non_streaming() for _ in range(n)]
chat_completions = await asyncio.gather(*tasks)
successful_completions = [c for c in chat_completions if c is not None]
print(n, time.time() - start, len(successful_completions))
def get_utc_datetime():
import datetime as dt
from datetime import datetime
if hasattr(dt, "UTC"):
return datetime.now(dt.UTC) # type: ignore
else:
return datetime.utcnow() # type: ignore
# Run the event loop to execute the async function
async def parent_fn():
for _ in range(10):
dt = get_utc_datetime()
current_minute = dt.strftime("%H-%M")
print(f"triggered new batch - {current_minute}")
await loadtest_fn()
await asyncio.sleep(10)
asyncio.run(parent_fn())
Multi-Instance TPM/RPM Load Test (Proxy)
Test if your defined tpm/rpm limits are respected across multiple instances.
The quickest way to do this is by testing the proxy. The proxy uses the router under the hood, so if you're using either of them, this test should work for you.
In our test:
- Max RPM per deployment is = 100 requests per minute
- Max Throughput / min on proxy = 200 requests per minute (2 deployments)
- Load we'll send to proxy = 600 requests per minute
So we'll send 600 requests per minute, but expect only 200 requests per minute to succeed.
If you don't want to call a real LLM API endpoint, you can setup a fake openai server. See code
1. Setup config
model_list:
- litellm_params:
api_base: http://0.0.0.0:8080
api_key: my-fake-key
model: openai/my-fake-model
rpm: 100
model_name: fake-openai-endpoint
- litellm_params:
api_base: http://0.0.0.0:8081
api_key: my-fake-key
model: openai/my-fake-model-2
rpm: 100
model_name: fake-openai-endpoint
router_settings:
num_retries: 0
enable_pre_call_checks: true
redis_host: os.environ/REDIS_HOST ## 👈 IMPORTANT! Setup the proxy w/ redis
redis_password: os.environ/REDIS_PASSWORD
redis_port: os.environ/REDIS_PORT
routing_strategy: usage-based-routing-v2
2. Start proxy 2 instances
Instance 1
litellm --config /path/to/config.yaml --port 4000
## RUNNING on http://0.0.0.0:4000
Instance 2
litellm --config /path/to/config.yaml --port 4001
## RUNNING on http://0.0.0.0:4001
3. Run Test
Let's hit the proxy with 600 requests per minute.
Copy this script 👇. Save it as test_loadtest_proxy.py AND run it with python3 test_loadtest_proxy.py
from openai import AsyncOpenAI, AsyncAzureOpenAI
import random, uuid
import time, asyncio, litellm
# import logging
# logging.basicConfig(level=logging.DEBUG)
#### LITELLM PROXY ####
litellm_client = AsyncOpenAI(
api_key="sk-1234", # [CHANGE THIS]
base_url="http://0.0.0.0:4000"
)
litellm_client_2 = AsyncOpenAI(
api_key="sk-1234", # [CHANGE THIS]
base_url="http://0.0.0.0:4001"
)
async def proxy_completion_non_streaming():
try:
client = random.sample([litellm_client, litellm_client_2], 1)[0] # randomly pick b/w clients
# print(f"client={client}")
response = await client.chat.completions.create(
model="fake-openai-endpoint", # [CHANGE THIS] (if you call it something else on your proxy)
messages=[{"role": "user", "content": f"This is a test: {uuid.uuid4()}"}],
)
return response
except Exception as e:
# print(e)
return None
async def loadtest_fn():
start = time.time()
n = 600 # Number of concurrent tasks
tasks = [proxy_completion_non_streaming() for _ in range(n)]
chat_completions = await asyncio.gather(*tasks)
successful_completions = [c for c in chat_completions if c is not None]
print(n, time.time() - start, len(successful_completions))
def get_utc_datetime():
import datetime as dt
from datetime import datetime
if hasattr(dt, "UTC"):
return datetime.now(dt.UTC) # type: ignore
else:
return datetime.utcnow() # type: ignore
# Run the event loop to execute the async function
async def parent_fn():
for _ in range(10):
dt = get_utc_datetime()
current_minute = dt.strftime("%H-%M")
print(f"triggered new batch - {current_minute}")
await loadtest_fn()
await asyncio.sleep(10)
asyncio.run(parent_fn())
Extra - Setup Fake OpenAI Server
Let's setup a fake openai server with a RPM limit of 100.
Let's call our file fake_openai_server.py.
# import sys, os
# sys.path.insert(
# 0, os.path.abspath("../")
# ) # Adds the parent directory to the system path
from fastapi import FastAPI, Request, status, HTTPException, Depends
from fastapi.responses import StreamingResponse
from fastapi.security import OAuth2PasswordBearer
from fastapi.middleware.cors import CORSMiddleware
from fastapi.responses import JSONResponse
from fastapi import FastAPI, Request, HTTPException, UploadFile, File
import httpx, os, json
from openai import AsyncOpenAI
from typing import Optional
from slowapi import Limiter
from slowapi.util import get_remote_address
from slowapi.errors import RateLimitExceeded
from fastapi import FastAPI, Request, HTTPException
from fastapi.responses import PlainTextResponse
class ProxyException(Exception):
# NOTE: DO NOT MODIFY THIS
# This is used to map exactly to OPENAI Exceptions
def __init__(
self,
message: str,
type: str,
param: Optional[str],
code: Optional[int],
):
self.message = message
self.type = type
self.param = param
self.code = code
def to_dict(self) -> dict:
"""Converts the ProxyException instance to a dictionary."""
return {
"message": self.message,
"type": self.type,
"param": self.param,
"code": self.code,
}
limiter = Limiter(key_func=get_remote_address)
app = FastAPI()
app.state.limiter = limiter
@app.exception_handler(RateLimitExceeded)
async def _rate_limit_exceeded_handler(request: Request, exc: RateLimitExceeded):
return JSONResponse(status_code=429,
content={"detail": "Rate Limited!"})
app.add_exception_handler(RateLimitExceeded, _rate_limit_exceeded_handler)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# for completion
@app.post("/chat/completions")
@app.post("/v1/chat/completions")
@limiter.limit("100/minute")
async def completion(request: Request):
# raise HTTPException(status_code=429, detail="Rate Limited!")
return {
"id": "chatcmpl-123",
"object": "chat.completion",
"created": 1677652288,
"model": None,
"system_fingerprint": "fp_44709d6fcb",
"choices": [{
"index": 0,
"message": {
"role": "assistant",
"content": "\n\nHello there, how may I assist you today?",
},
"logprobs": None,
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21
}
}
if __name__ == "__main__":
import socket
import uvicorn
port = 8080
while True:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
result = sock.connect_ex(('0.0.0.0', port))
if result != 0:
print(f"Port {port} is available, starting server...")
break
else:
port += 1
uvicorn.run(app, host="0.0.0.0", port=port)
python3 fake_openai_server.py